crewAI实践(包含memory的启用)--AiRusumeGenerator
-----------------------------------------------
@TOC
什么是crewAI
Cutting-edge framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, CrewAI empowers agents to work together seamlessly, tackling complex tasks.
CrewAI 是一个前沿的框架,用于组织和协调角色扮演的自主AI代理。通过促进协作智能,它使代理能够无缝地协同工作,应对复杂任务。
AiRusumeGenerator
ai智能简历在线生成器,一个有点用,但用处不多的多智能体应用。代码在最后。
项目相关文章:
memory的启用,避开openai
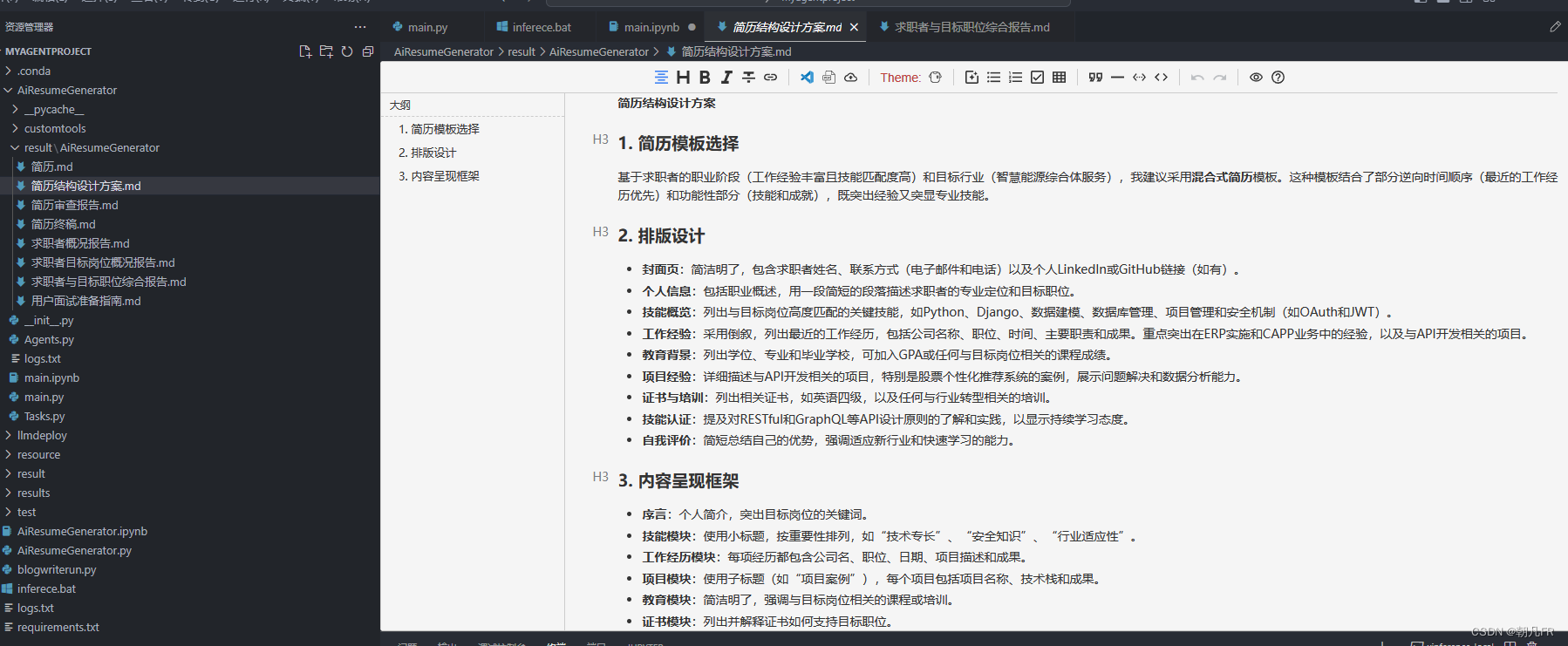
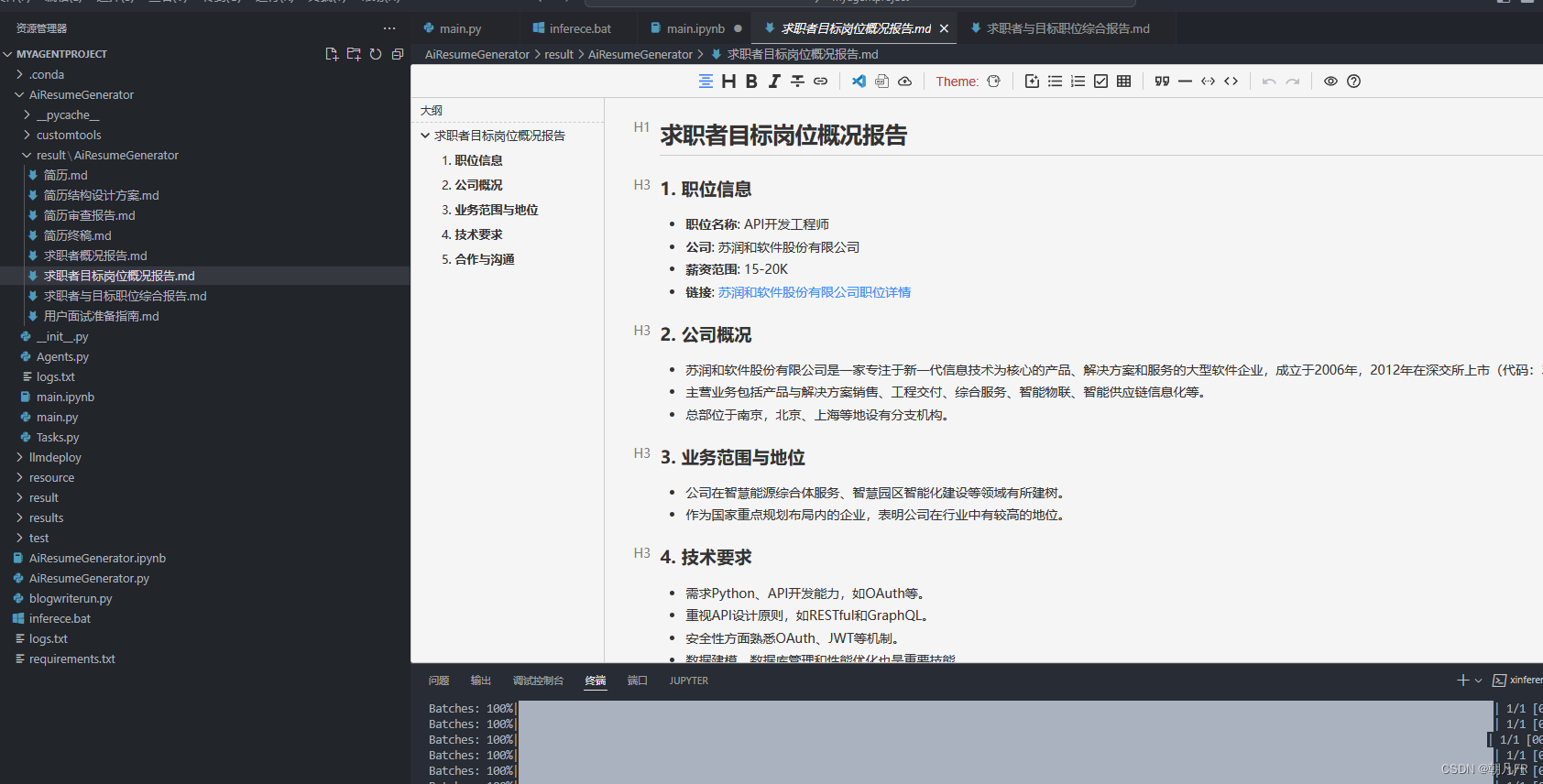
功能效果展示
简历结构设计方案
求职着目标岗位概况
开发背景
最近在准备找工作,准备简历是个烦心的事情,恰好在微信公众号看到了crewAI的介绍,又恰好看到官方案例中有简历优化这样一个应用,于是花了一个星期来学习以及使用这款框架,不得不说目前的大模型诞生在国外这一事实造成了很多麻烦,很多AI框架都是围绕着openai开发的。但是,费点力气还是能克服的。
开发步骤
1. 首先得学习下这款框架
这里是学习视频网址。
原理
简单说说我的理解,其原理就是将一个可能比较复杂的任务,比如生成一个简历。。。如果你直接让大模型给你,其实也是可以的,给出的结果有时候可能也还不错,但是就是感觉不是想要的结果,想要改就得不断的修改提示词去调整,才有可能得到想要的结果。
但是懒惰是人的本性,我想要的是我把我的个人信息材料和我目标岗位的信息提供给你,然后你直接给我一份针对性的定制性的简历,最好还能提供一些岗位匹配报告、面试指南等等,这一切都要是针对性的。那么这就是一个复杂的业务流程了。
而复杂的业务流程实现高质量结果的核心就是分工合作,每个人专注自己的事情。据官方提供的信息大模型同样据有此种特性。
由于之前在erp行业干过一年半,所以我对SOP标准作业程序这一概念有所了解,我发现这个概念和crewAI可以说是相当契合了。
于是我们的第一个问题就是,一个简历的标准制作流程是什么?想当然的我认为现在的猎头公司应当有这项任务。什么?没干过猎头,不知道是他有什么业务?很简单,问AI嘛

好的,流程有了,那么所谓的专人专事,什么人做什么呢?依旧不知道,当然还是问AI:

好的,应用的基本运行逻辑也就有了,但是一个好的SOP应该每一个关键步骤都有其标准的结果文档才行,那么好,继续问ai:

ok,到目前为止,一个简历生成器的基本运行逻辑有了,下面就是如何利用crewAI框架去实现了。
大概用法
简单浏览下其官方文档,大概步骤是这样
(1) 解决大模型的使用问题
直接给答案:
from langchain_community.chat_models import ChatZhipuAI,ChatTongyi
import os
#两种大模型,一个是阿里的大模型Qwen,一个是智谱AI的glm4
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["ZHIPUAI_API_KEY"] = ""
#为memeory的启用而设置,国内用不了openai,也不想用,url是本地部署的xinference服务,兼容openai的api
os.environ['OPENAI_API_BASE'] ="http://localhost:9997/v1"
os.environ['OPENAI_API_KEY'] = 'not empty'
zhipullm = ChatZhipuAI(
model="glm-4",
temperature=0.6,
max_tokens = 4096,
)
TongyiQW = ChatTongyi(
model="qwen-turbo",
max_tokens = 4096,
temperature=0.7
)
# 设个变量好赋值
llm = TongyiQW (2) 关键概念,设置agent
这里仅仅展示其中一个,构造可以说是相当简单
其实也展现了一种格式化的提示词写作方法,确定角色、目标、背景,这些就是人类的人设。作为模拟人工智能的大模型也是如此。
# 初始化Agent对象,设置其角色、目标、背景故事以及其他配置
ICNS = Agent(
role="信息收集与分析专员",
goal="深入了解求职者,精准把握职位需求,为简历制作提供详实基础。",
backstory="1. 作为一家猎头公司求职项目组的信息收集与分析专员,你所在的项目组正在协助求职者准备他的简历。"
"2. 你将负责通过求职者提供的材料,深入了解其背景、经历、技能及职业目标。"
"3. 你需要收集并整理求职者提供的所有相关材料,包括现有简历、项目案例、证书等。"
"4. 你需要深入分析目标职位的详细要求,明确招聘方的偏好和需求。",
#是否允许智能体生成任务分配给其他智能体
allow_delegation=False,
#不使用openai必须单独指定大模型,否则其会默认使用openai
llm=llm,
verbose=True,
)
(3) 关键概念,设置task
任务也就是程序步骤,关键在description和expected_output,即任务描述和生成什么样的结果。以及什么人去执行,需要用到什么工具。工具是另一个核心概念。
applicant_analysis = Task(
name="求职者信息收集与分析",
description="1. 通过求职者提供的材料,深入了解和分析其背景、经历、技能及职业目标等。"
"2. 如果在材料中发现有可以打开的url,可以尝试使用网页抓取工具获取更多信息进行分析。"
"2. 撰写求职者概况报告,要求汇总求职者关键信息。",
expected_output = "一份详细且准确的Markdown格式的求职者概况报告,汇总求职者关键信息。",
agent = agent,
tools = [FileReadTool,scrapeWebsiteTool],
#将大模型得出的结果存到文件里
output_file = "result/AiResumeGenerator/求职者概况报告.md",
#没有文件目录时自动创建
create_directory=True,
#异步执行,就是没执行完也可以执行下一个
async_execution=True,
)
(4) 关键概念,crew
crew是船员的意思,意思是将上面设置的agent与task结合到一起,形成一个完整的团体,也是一个完整的工作流程。
crew = Crew(
agents=[info_collection_analysis_specialist, resume_architect,content_editor,quality_control_expert,customer_manager],
tasks=[info_collection_analysis, resume_structure_design,content_creation_filling,content_review_optimization,joint_resume_review],
verbose=2, # You can set it to 1 or 2 to different logging levels
memory=True,
output_log_file = True,
#据说这里也可以指定代理用什么模型会覆盖agent里面的llm设置
#function_calling_llm = zhipullm,
#memeory启用时,embeddr也必须启用,不然会默认使用openai
embedder={
"provider": "openai",
"config":{
#这是通过xinference框架提供的服务,因为在之前设置了openai的baseurl环境变量
"model": 'custom-embedding-bge-large-zh-v1.5'
}
}
)能够用来做什么?
了解了大体框架原理以及用法,用来能做什么你们心理应该也有数了。
用官方的话来说,这其实是一种新型的编程方式,整个软件运行过程中的每一步,只有软件的流程是确定的(当然开启了层级流程控制,流程也不确定了),输入是模糊的,输出也是模糊的,这里的模糊对比于以前编程函数中的输入和输出,以前我们程序中的每一步骤的数据类型、数据值都是确定的,而crewAI程序不同,只有输入输出的类型是确定的都是字符串,但是值每一次可能都是不同的,这也是ai的魅力所在。
且个人感觉crewAI已经有了半面向自然语言编程的味道了。
最后,出于我狭窄的视野,crewAI能够用来做所有的文字类工作,好像是句废话,但是现在的咨询公司、自媒体等等,都是可以被取代的。
2. 安装crewAI以及使用概述
这里不再赘述,直接引用前辈的贡献。多Agent协作工具CrewAI使用指南
3. 写代码
由于代码长度的问题,agent、task、crew启动单独封装在不同的文件
Agents.py
from crewai import Agent
class Agents():
"""
Agents class : This class is used to create agents
function: manager,icns,resume_architect,content_editor,qce,interviewCoach
"""
def manger(self,llm):
"""
创建一个表示项目经理的Agent对象,该对象具有特定的角色、目标、背景故事,并允许委托和详细输出。
参数:
self: 对象实例,通常在类方法中使用,表示当前类的实例。
llm: (类型未指定) - 这个参数的用途需要具体上下文来确定,可能是某种管理资源或配置。
返回:
manager: Agent对象 - 包含项目经理角色信息的实例,具备管理功能和配置的Agent。
注意:
- Agent对象的角色是"项目经理",其目标是高效管理团队并保证任务质量。
- 背景故事描述了项目经理的角色职责,包括协调团队和确保任务按期高质量完成。
- 允许代理(allow_delegation=True)意味着该角色可以将部分任务委派给其他对象。
- 设置为verbose=True,意味着Agent在执行操作时会提供详细的输出信息。
"""
manager = Agent(
role="项目经理",
goal="高效管理团队,确保高质量完成任务",
backstory="您是一位经验丰富的项目经理,擅长监督复杂项目并引领团队走向成功。您的职责是协调团队成员的努力,确保每项任务按时完成并达到最高标准。",
allow_delegation=True,
verbose=True,
llm = llm,
)
return manager
def icns(self, llm):
"""
创建一个信息收集与分析专员的Agent实例。
该函数用于初始化一个名为ICNS的Agent对象,该对象将扮演信息收集与分析专员的角色,
其主要职责是深入了解求职者背景和职位需求,为简历制作提供支持。
参数:
- llm: 低层模型的缩写,具体用途未说明,可能是一个用于辅助分析的模型或算法。
返回:
- 返回创建的ICNS Agent实例。
"""
# 初始化Agent对象,设置其角色、目标、背景故事以及其他配置
ICNS = Agent(
role="信息收集与分析专员",
goal="深入了解求职者,精准把握职位需求,为简历制作提供详实基础。",
backstory="1. 作为一家猎头公司求职项目组的信息收集与分析专员,你所在的项目组正在协助求职者准备他的简历。"
"2. 你将负责通过求职者提供的材料,深入了解其背景、经历、技能及职业目标。"
"3. 你需要收集并整理求职者提供的所有相关材料,包括现有简历、项目案例、证书等。"
"4. 你需要深入分析目标职位的详细要求,明确招聘方的偏好和需求。",
allow_delegation=False,
llm=llm,
verbose=True,
)
return ICNS
def resume_architect(self,llm):
"""
创建一个代理角色,负责高级简历架构师的工作。
该函数初始化一个Agent对象,配置了该角色的相关属性,如角色名称、目标、背景故事等,
以及是否允许委托和使用的LLM模型等设置。
参数:
llm: Large Language Model的缩写,推测是指用于辅助简历设计的语言模型。
返回:
返回初始化后的Agent对象,该对象代表了高级简历架构师的角色。
"""
resume_architect = Agent(
role="高级简历架构师",
goal="设计简历布局,确保内容结构清晰、吸引眼球,符合求职者身份及目标职位特点。",
backstory="1. 作为一家猎头公司求职项目组的简历架构师,你所在的项目组正在协助求职者准备他的简历。"
"2. 你将负责根据信息收集与分析专员的报告,选择最适合求职者的简历模板和结构。"
"3. 你需要设计简历的整体布局,确保视觉上的吸引力和内容的逻辑性。"
"4. 你需要制定简历各部分内容的呈现框架,指导内容编辑人员如何组织信息。",
allow_delegation=False,
llm=llm,
verbose=True,
)
return resume_architect
def content_editor(self,llm):
"""
创建一个Agent对象,扮演资深内容编辑师的角色,负责编写高质量的简历内容。
参数:
llm - 大语言模型的实例,用于协助编辑师生成和优化简历内容。
返回:
content_editor - 资深内容编辑师的Agent对象,具备特定的角色、目标、背景和行为设置。
"""
content_editor = Agent(
role = "资深内容编辑师",
goal = "编写高质量、针对性强的简历内容,凸显求职者优势,提升简历吸引力。",
backstory = "1. 作为一家猎头公司求职项目组的内容编辑师,你所在的项目组正在协助求职者准备他的简历。"
"2. 你需要在简历架构师的指导下,负责不同部分的内容撰写和优化,如个人信息、职业目标、工作经验、项目经历、教育背景、技能清单等。"
"3. 你需要确保每部分内容精准、突出亮点,符合目标职位的要求。"
"4. 你需要对接信息收集与分析专员,确保信息的准确性和最新性。",
allow_delegation=False,
llm=llm,
verbose=True,
)
return content_editor
def qce(self,llm):
"""
创建一个质量控制专家代理
该函数用于初始化并返回一个质量控制专家的角色代理。质量控制专家负责审核简历,
确保其质量达到高标准,无错误,内容准确且具有专业性和吸引力。
参数:
llm (object): 语言模型接口,用于代理与语言模型之间的交互。
返回:
Agent: 质量控制专家的角色代理实例。
"""
quality_control_expert = Agent(
role = "质量控制专家",
goal = "严格把关简历质量,保证无错误,内容准确、专业,提升整体表现力。",
backstory = "1. 作为一家猎头公司求职项目组的质量控制专家,你所在的项目组正在协助求职者准备他的简历。"
"2. 你需要进行简历的全面审核,包括语法、拼写、逻辑性、语言风格等方面的检查。"
"3. 你需要确保简历符合行业标准,且具有高度的专业性和吸引力。"
"4. 你需要协调内容编辑师进行必要的修订,直至达到高标准。",
allow_delegation=True,
llm=llm,
verbose=True,
)
return quality_control_expert
def interviewCoach(self,llm):
"""
创建一个面试辅导顾问的Agent对象,旨在帮助求职者准备面试。
该顾问将根据求职者的目标职位,提供个性化的面试准备策略,包括公司文化了解、职位要求解析和行业动态把握等方面。
参数:
llm: 一个语言模型的实例,用于生成有关面试准备的建议和解答求职者的问题。
返回:
一个配置了特定角色、目标、背景故事和行为模式的Agent对象,专注于面试辅导功能。
"""
interviewCoach = Agent(
role = "面试辅导顾问",
goal = "根据目标职位,帮助求职者深入了解公司文化、职位要求及行业动态,准备与职位相关的案例和问题解答。",
backstory = "1. 作为一家猎头公司求职项目组的面试辅导顾问,你所在的项目组已经完成简历的制作,现在你需要协助求职者准备面试。"
"2. 你需要根据面试者的简历和目标职位,分析针对该职位的面试准备的要点。"
"3. 你需要尽可能全面的考虑求职者面试其目标职位时可能遇到的情况。"
"4. 你需要确保你做的工作能够帮助求职者有更大的机会通过面试。",
allow_delegation=False,
llm=llm,
verbose=True,
)
return interviewCoach
Tasks.py
from crewai import Task
from crewai_tools import ScrapeWebsiteTool
from customtools.BaiduSearch import BaiduSearchTool
from customtools.ChineseFileRead import ChineseFileReadTool
class Tasks():
def applicant_analysis(self,agent,file_path):
FileReadTool=ChineseFileReadTool(file_path=file_path)
scrapeWebsiteTool=ScrapeWebsiteTool()
applicant_analysis = Task(
name="求职者信息收集与分析",
description="1. 通过求职者提供的材料,深入了解和分析其背景、经历、技能及职业目标等。"
"2. 如果在材料中发现有可以打开的url,可以尝试使用网页抓取工具获取更多信息进行分析。"
"2. 撰写求职者概况报告,要求汇总求职者关键信息。",
expected_output = "一份详细且准确的Markdown格式的求职者概况报告,汇总求职者关键信息。",
agent = agent,
tools = [FileReadTool,scrapeWebsiteTool],
output_file = "result/AiResumeGenerator/求职者概况报告.md",
create_directory=True,
async_execution=True,
)
return applicant_analysis
def targetjob_analysis(self,agent,file_path):
FileReadTool=ChineseFileReadTool(file_path=file_path)
scrapeWebsiteTool=ScrapeWebsiteTool()
baiduSearchTool = BaiduSearchTool()
targetjob_analysis = Task(
name="求职者目标岗位信息收集与分析",
description="1. 通过求职者提供的材料,深入了解其目标岗位相关信息,包括但不限于岗位职责、岗位要求、岗位所在行业、目标岗位所在公司概况等。"
"2. 若目标岗位所在公司信息不足,可以尝试使用网页搜索工具获取更多信息进行分析。"
"3. 如果在获得的所有信息中发现有可以打开的url,可以尝试使用网页抓取工具获取更多信息进行分析。"
"4. 根据获得的所有信息,撰写求职者目标岗位概况报告,要求汇总求职者目标岗位关键信息。",
expected_output = "一份详细且准确的Markdown格式的求职者目标岗位概况报告,汇总求职者目标岗位关键信息。",
agent = agent,
tools = [FileReadTool,scrapeWebsiteTool,baiduSearchTool],
output_file = "result/AiResumeGenerator/求职者目标岗位概况报告.md",
create_directory=True,
async_execution=True,
)
return targetjob_analysis
def application_analysis(self,agent,context):
application_analysis = Task(
name="求职者与目标职位综合分析",
description="1. 通过求职者概况报告和求职者目标岗位概况报告联合分析,内容包括但不限于:求职者与目标职位的匹配度、求职者与目标职位的差异性、求职者与目标职位的共性以及求职者简历内容建议。",
expected_output = "一份详细且准确的Markdown格式的求职者与目标职位综合报告。",
agent = agent,
output_file = "result/AiResumeGenerator/求职者与目标职位综合报告.md",
create_directory=True,
context = context,
)
return application_analysis
def resume_structure_design(self,agent,context):
resume_structure_design = Task(
name = "简历结构设计",
description="1. 根据求职者的职业阶段和目标行业,选择合适的简历模板(如逆向时间顺序、功能性或混合式简历)。"
"2. 设计清晰、专业的排版,确保简历易于阅读,重点突出。考虑使用清晰的字体、合适的字号、恰当的标题和子标题。"
"3. 最后根据你完美的设计,撰写简历结构设计方案,包括但不限于简历模板、各部分内容概要及设计说明等。",
expected_output = "一份Markdown格式的简历结构设计方案,包括但不限于简历模板、各部分内容概要及设计说明等。",
agent = agent,
output_file = "result/AiResumeGenerator/简历结构设计方案.md",
create_directory=True,
context = context
)
return resume_structure_design
def writing_resume(self,agent,context):
content_creation_filling = Task(
name = "求职者简历制作",
description="1. 根据简历结构设计方案以及求职者概况报告,编写并填充简历的每个部分,确保内容精确、突出亮点。"
"2. 撰写简历,确保内容准确、完整、专业且整体符合简历结构设计方案要求。"
"3. 如果质量控制专家或者高级简历架构师对完成的简历不满意,根据他们的建议进行简历内容的修正和优化。",
expected_output = "一份精心设计的Markdown格式的个人求职简历。",
agent = agent,
output_file = "result/AiResumeGenerator/简历.md",
create_directory=True,
context = context,
)
return content_creation_filling
def content_review_optimization(self,agent,context):
content_review_optimization = Task(
name = "内容审查与优化",
description="1. 对简历内容进行全面审查,包括语法、拼写、逻辑、表述清晰度及专业术语的正确使用。"
"2. 与资深内容编辑师和高级简历架构师沟通简历的优化与修正。"
"3. 撰写内容审查报告,记录所有修改建议、已更正的错误及优化点。",
expected_output = "一份Markdown格式的简历内容审查报告,记录着所有修改建议及优化点。",
agent = agent,
output_file = "result/AiResumeGenerator/简历审查报告.md",
create_directory=True,
context = context
)
return content_review_optimization
def resume_finalization(self,agent,context):
resume_finalization = Task(
name = "简历修订",
description="1. 根据简历审查报告提供的建议修订简历,完成简历的优化。",
expected_output = "一份Markdown格式的简历。",
agent = agent,
output_file = "result/AiResumeGenerator/简历终稿.md",
create_directory=True,
context = context
)
return resume_finalization
def interview_prep(self, agent, context):
interview_prep = Task(
name = "面试准备指南制作",
description="1. 根据求职者与目标职位综合报告和最终修订好的简历,制作面试准备指南。",
expected_output = "一份精心制作且量身订制的Markdown格式的面试准备指南。",
agent = agent,
output_file = "result/AiResumeGenerator/用户面试准备指南.md",
create_directory=True,
context = context,
async_execution=True,
)
return interview_prep
mian.py
from Agents import Agents
from Tasks import Tasks
from crewai import Crew,Process
from langchain_community.chat_models import ChatZhipuAI,ChatTongyi
import os
os.environ["DASHSCOPE_API_KEY"] = "******************"
os.environ["ZHIPUAI_API_KEY"] = "**********************"
os.environ['OPENAI_API_BASE'] = 'http://localhost:9997/v1'
os.environ['OPENAI_API_KEY'] = 'not empty'
zhipullm = ChatZhipuAI(
model="glm-4",
temperature=0.6,
max_tokens = 4096,
)
TongyiQW = ChatTongyi(
model="qwen-turbo",
max_tokens = 4096,
temperature=0.7
)
llm = TongyiQW
Agents = Agents()
agent1 = Agents.manger(llm)
agent2 = Agents.icns(llm)
agent3 = Agents.resume_architect(llm)
agent4 = Agents.content_editor(llm)
agent5 = Agents.interviewCoach(llm)
agent6 = Agents.qce(llm)
Tasks = Tasks()
#path_file 指向文件为用户的个人信息文件
task1 = Tasks.applicant_analysis(agent=agent2,file_path=r"D:\crewAI\myagentproject\resource\AiResumeGenerator\custominformation.md")
#这里path_file 指向文件为用户目标岗位的相关信息
task2 = Tasks.targetjob_analysis(agent=agent2,file_path=r"D:\crewAI\myagentproject\resource\AiResumeGenerator\targetjob.txt")
task3 = Tasks.application_analysis(agent=agent2,context=[task1,task2])
task4 = Tasks.resume_structure_design(agent=agent3,context=[task3])
task5 = Tasks.writing_resume(agent=agent4,context=[task4,task1])
task6 = Tasks.content_review_optimization(agent=agent6,context=[task5])
task7 = Tasks.resume_finalization(agent=agent4,context=[task6,task5])
task8 = Tasks.interview_prep(agent=agent5,context=[task3,task7])
crew = Crew(
agents=[agent2, agent3, agent4, agent5, agent6],
tasks=[task1, task2, task3, task4, task5, task6, task7, task8],
verbose=2, # You can set it to 1 or 2 to different logging levels
memory=True,
output_log_file = True,
#function_calling_llm = zhipullm,
embedder={
"provider": "openai",
"config":{
"model": 'custom-embedding-bge-large-zh-v1.5'
}
},
share_crew = False,
)
crew.kickoff()